
by Xiaoya Liao (SID:540785708)
Content Plunder: How Is AI Threatening Creators
On October 22, 2024, more than 10,500 creative professionals around the world jointly issued a statement accusing generative AI of using their work training models without authorization, posing a serious threat to the livelihoods of creators and a major violation of their creative rights and interests.

The above is the content of the statement jointly signed by numerous artists and practitioners. Despite its brevity, it conveys the profound concerns of creators and professionals about AI. Prior to this joint statement and protest, tensions had already simmered for months between AI developers and artists, who argue that their works are being used without proper consent or compensation. Strikes by the SAG-AFTRA union and the Writers Guild of America have already hit the entertainment industry.
This incident has exposed the dark underbelly of the AI industrial chain: a supposedly groundbreaking technology symbolizing innovation is, in reality, advancing in a ‘blood-soaked’ manner by exploiting humanity’s inherent creativity. Ironically, AI-generated ‘creative outputs’ are now devouring the very space for human originality.
For instance, the 2024 Akutagawa Prize, Japan’s prestigious literary award, sparked controversy when it was awarded to Tokyo Sympathy Tower, a novel co-created with AI. Critics argue that such works parasitize the raw creative reservoirs of human authors while masquerading as “efficiency”, ultimately suffocating genuine creators. This not only exposes AI’s copyright pitfalls, but also reveals its suffocation of human creativity,
The Death of Creativity: When Thinking Becomes a Luxury
The illusion of “creation” fabricated by AI is eroding the very foundation of human creativity. Today, anyone can use generative AI tools to instantly produce a novel by simply inputting plot keywords. Tools like ChatGPT can generate entire chapters through deep analysis, and with sufficient training, they can even mimic specific tones. For instance, churning out a clichéd Mary Sue romance novel in the style of J.K. Rowling.
While these tools superficially liberate creative efficiency, they conceal a deeper crisis: humans are relinquishing the right to think, outsourcing cognition to AI. These systems analyze vast troves of data (with copyright risks) to synthesize answers that mimic human reasoning, which represents a dangerous intellectual complacency. For example, a 2023 survey revealed that a staggering 89% of American college students now use ChatGPT to complete their assignments:
- Over 9 in 10 students are aware of ChatGPT, far more than grade school educators.
- Over 89% of students have used ChatGPT to help with a homework assignment.
- 48% of students admitted to using ChatGPT for an at-home test or quiz, 53% had it write an essay, and 22% had it write an outline for a paper.
- Surprisingly, 72% of college students believe that ChatGPT should be banned from their college’s network.
- Perhaps we can thank the 15% of educators who have used ChatGPT to discuss the moral implications of technology as a reason why more students see the negative implications of the AI tool in education.
That same year, the Stanford Daily also conducted an informal survey and found that some students were even using ChatGPT in their final exams:
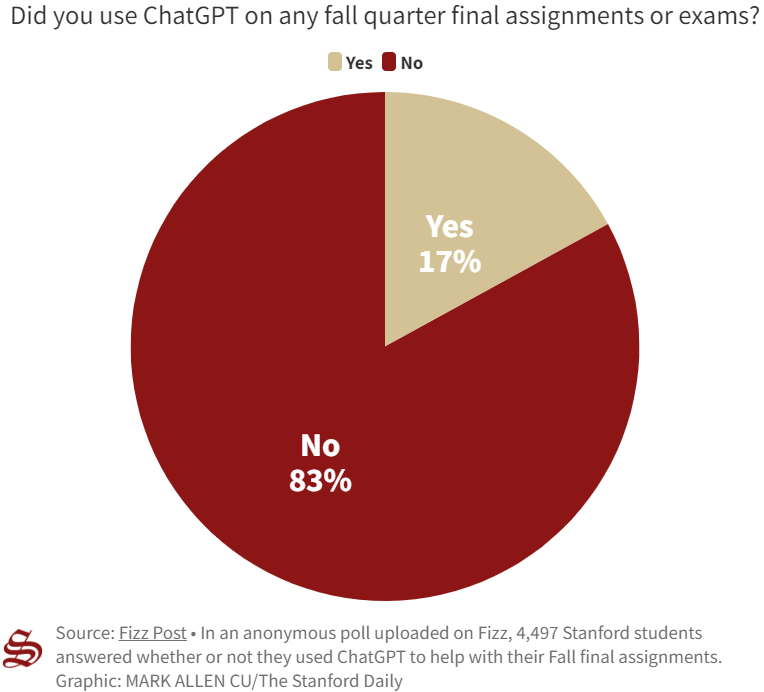
“According to the poll, which had 4,497 respondents (though the number may be inflated) and was open from Jan. 9 to Jan. 15, around 17% of Stanford student respondents reported using ChatGPT to assist with their fall quarter assignments and exams. Of those 17%, a majority reported using the AI only for brainstorming and outlining. Only about 5% reported having submitted written material directly from ChatGPT with little to no edits, according to the poll.”
What we’ve observed is that while many tout AI as a tool to “provide inspiration,” the reality is starkly different. When prefabricated answers lie readily at hand, how many can resist the temptation to simply take them? Worse yet, these tools constrain users’ thinking, trapping them within the confines of AI-generated outputs. Moreover, the underlying logic of generative AI is to analyze and output the existing data system, which can only reheat “dishes” cooked by predecessors. What masquerades as innovation is merely a deceptive collage of borrowed contents.
We must also confront digital capitalism’s grip on this technology: efficiency. Under capitalist imperatives, technology lacks true autonomy. Its development is shackled to capital’s demands: capital births technology. And only those tools that serve capital’s hunger for profit survive. ChatGPT and similar generative language models, which we might collectively term machine language, emerge and evolve as substitutes for human labor. This new labor form analyzed humanity’s millennia-old cultural heritage, shredding it into algorithmically replicable templates.
In China, online fiction platforms have been exposed for stealthily revising terms of service to freely feed their AI with viral works, flooding their sites with AI-generated novels in order to create greater economic benefits. These stories share a fatal flaw: they cram every trending trope into plots, very attractive, but also highly similar to no new ideas, standard but soulless. In the result, We are witnessing a ‘cultural metabolism’, where diversity is murdered by efficiency.

On Dec. 9, OpenAI made its artificial intelligence video generation model Sora publicly available in the U.S. and other countries.
Data Enclosure : How Did We Become Digital Serfs
As we all know, in the name of “advancing human progress,” tech giants like OpenAI exploit global creators’ data to train their models without authorization. In doing so, they privatize intellectual labor( knowledge and creative outputs that rightfully belong to individuals or the public domain) transforming them into proprietary assets for commercial monopolies. This mirrors the 15th-19th century British enclosure movement, where emerging capitalists and aristocrats seized communal lands. Today, data has become the “new oil” of the digital age. Technology giants are engaged in the “data enclosure” movement by seizing and controlling massive data content (such as user behavior and creative content), birthing a new digital class hierarchy. Just as farmers lost control of their lands, modern creators are stripped of sovereignty over their intellectual outputs, becoming the “digital serfs” of the new age.
| Emerging Capitalists and Aristocrats | Emerging Tech Giants |
| Taking Communal Lands | Plundering Vast Datas |
| Farmers | Modern Creators |
| Losing Control of Their Lands | Losing Control of Their Intellectual Outputs |
What Can We Do
Solutions and Worries of Copyright Dilemmas
Example:the UK’s “Opt-Out” Model
Following the joint statement (October 22, 2024), the UK government accelerated efforts to regulate AI copyright practices under mounting public pressure, aiming to regulate tech companies’ use of copyrighted content to train their AI models. As reported by CNBC, a public consultation launched on December 17 seeks to improve clarity for creative industries and AI developers on how AI companies acquire intellectual property and use it for training purposes:
- boosting trust and transparency between sectors, by ensuring AI developers provide right holders with greater clarity about how they use their material.
- enhancing right holders’ control over whether or not their works are used to train AI models, and their ability to be paid for its use where they so wish.
- ensuring AI developers have access to high-quality material to train leading AI models in the UK and support innovation across the UK AI sector.
Yet this consultation has sparked fierce backlash from creators and industry leaders. The proposal includes broad new copyright exceptions for commercial generative AI training, permitting companies to use UK-copyrighted works without licenses unless rights holders explicitly opt out. At the heart of the dispute the “opt-out system” would allow AI firms to freely mine protected content by default, a framework that critics call a “presumption of theft.”
The UK government argues this model will foster an AI-friendly regulatory environment, attracting investment (particularly from US tech giants). However, opponents condemn it as a fundamental betrayal of creators’ rights. By prioritizing AI industry growth over IP protections, the policy risks sacrificing the UK’s £126 billion-a-year creative sector, spanning publishing, music, and film, to subsidize corporate profits.
A Flawed System
The “opt-out” mechanism exists in an idealistic vacuum. Not only do tech giants remain largely unaffected (since the burden of action falls on individual creators, not the companies seeking to use their work), but the proposal also unilaterally burdens creators while being riddled with practical flaws. Submitting opt-out requests for individual works is both time-consuming and resource-intensive. For example, on platforms like YouTube, a single takedown request can take up to 15 minutes to process. Protecting an entire portfolio of creative works, imposes a crushing administrative load on rights holders. Additionally, data shows that nearly 90% of creators are unaware they even have the option to opt out, leaving their work vulnerable to exploitation.
Generative AI and the Creative Industries
It is widely recognized that the creative industries are not only cultural assets but also vital economic drivers. Take the UK as an example: the creative sector contributes over £126 billion to the country’s GDP and provides millions of jobs. At its core, generative AI’s extraction of creator data for training serves one purpose—to allow tech companies to efficiently dominate this lucrative creative market and reap astronomical profits. In plain terms, Big Tech has set its sights on the creative market as a “cash cow,” competing with individual creators to monopolize market share and funnel all economic gains into corporate coffers. And they’re already succeeding. According to the latest CISAC report, the music industry alone is projected to lose nearly 25% of its revenue to AI-generated content within four years, with tech companies pocketing the profits.
Far from “democratizing creativity” as claimed in their marketing, these generative AI projects commodify creators’ works through technological monopolies. This raises deeper concerns: What future awaits the creative industries when AI systems prioritize scalability and profit over artistic integrity?
Balancing these competing interests must be the UK government’s priority. A coalition of major companies including Disney, Fox, Universal Music Group, and Getty Images has warned the government that the proposed “opt-out system” would empower AI firms to flood markets with low-cost AI-generated books, films, and music knockoffs, ultimately devaluing original creative works.
Meanwhile, creative leaders and industry groups propose an alternative: requiring explicit consent before using copyrighted materials for AI training. This approach aligns with established copyright practices, ensuring creators retain control over their intellectual property.
Preserving Deep Thinking, Upholding Creative Integrity
AI has made knowledge acquisition and generation astonishingly effortless—but can we retain our hunger for profound understanding and exploration? Will humanity still produce academic achievements in the future? To these questions, I remain optimistic.
If AI’s rapid filtering, synthesizing, and generating of knowledge is seen as exploiting humanity’s intellectual wealth, then humans too can evolve their cognitive frameworks at speed—or invent entirely new ones. At the heart of human cognition lies a hierarchy of judgment:
- Discern truth from falsehood: Is this real?
- Distinguish right from wrong: Is this justified?
- Assess value: Does this matter?
- Pass ethical judgment: Should this be celebrated or condemned?
This sequence is non-negotiable. We cannot leap to moral grandstanding—praising or condemning—before verifying basic facts. Yet today, as AI’s misuse increasingly demands human intervention, its capacity to fabricate narratives and spread misinformation has become alarmingly routine.
While AI possesses unparalleled advantages in absorbing, creating, and storing knowledge, it must not deviate from human cognitive frameworks. Humanity’s intellectual evolution has always been a dynamic interplay between knowledge accumulation and cognitive frameworks—each step forward in knowledge turns the wheel of cognitive models, propelling a spiral ascent where every iteration breaks old boundaries and explores uncharted territories.
To surrender this process to machines would be to forfeit our essence as meaning-makers. Let AI handle the how—but the why must forever remain human.
Regulation Breakthrough
United States: the COPIED Act Ushering in a New Era of AI-Generated Content Regulation
On July 11, 2024, the U.S. Congress passed the Content Origin Protection and Integrity Defiance Against Edited and Deepfake Media Act (abbreviated as the COPIED Act), aimed at addressing the proliferation of AI-generated “deepfakes” and protecting the rights of intellectual property holders.
Key Provisions of the COPIED Act:
- Establishing Transparency Standards:
The Act mandates the National Institute of Standards and Technology to develop new standards and watermarking systems for labeling, authenticating, and detecting AI-generated content. NIST is also tasked with creating cybersecurity measures to ensure the integrity of AI content origins and watermarks. - Protecting Creator Rights:
AI tool providers used for generating news or creative content must allow content owners to attach provenance information (e.g., authorship, usage terms). Unauthorized removal of such information is strictly prohibited. Training AI models or generating new AI content using works with provenance data without permission is banned. These measures empower creators (journalists, artists, songwriters, etc.) to set usage terms and compensation mechanisms. - Granting Individual Litigation Rights:
Beyond empowering the Federal Trade Commission and state attorneys general to enforce the Act, individual creators and rights holders may directly sue AI companies for unauthorized use of their works. - Prohibiting Tampering with AI Provenance:
The Act fills a legal gap by banning internet platforms, search engines, and social media companies from altering or disabling AI-generated content’s origin information.
European Union: World’s First “AI Act” Takes Effect (August 1, 2024)
EU Artificial Intelligence Act, the first comprehensive law regulating artificial intelligence globally, operates as a top-tier EU regulation and sets a benchmark for AI governance worldwide. Similar to the EU’s General Data Protection Regulation in data privacy, this legislation is poised to become a blueprint for AI laws in other jurisdictions.
The groundbreaking law categorizes AI systems into four risk tiers:
- Unacceptable Risk:
Banned entirely due to extreme societal threats (e.g. behavioral manipulation systems, social scoring). - High Risk:
Subject to strict compliance requirements in sectors like biometrics, education, employment, and critical infrastructure. - Limited Risk:
Requires basic transparency and disclosure (e.g. AI-powered chatbots). - Minimal Risk:
Light-touch regulation (e.g. most AI-driven games).
Global Governance in the AI Era
From the perspective of global governance, historical waves of disruptive technological innovation have liberated social productivity while simultaneously exacerbating socioeconomic crises: global developmental imbalances, wealth inequality, and lagging regulatory frameworks. Each technological revolution-driven globalization thrusts the world economy into profound realignment, inevitably triggering industrial decline, mass unemployment, and social instability. These challenges demand an upgraded and more robust global AI governance system.
The current runaway trajectory of AI technology fundamentally stems from capital’s capture of technological narratives. Exploiting legal-regulatory delays and monopolistic control over technology, capital has reframed AI as its profit-extraction tool. Yet AI’s potential transcends such narrow exploitation. Our imperative is to dismantle capital’s stranglehold on digital technologies, imposing constraints on its extractive logic. AI must not remain a “tool of exploitation”—it should be ethically harnessed to serve collective human welfare.
Reference
Browne, R. (2024, December 17). UK kicks off review into training AI models on copyrighted content. CNBC. https://www.cnbc.com/2024/12/17/uk-consults-on-rules-for-using-copyrighted-content-to-train-ai-models.html
Choi, C., Annio, F., & CNN. (2024, January 19). The winner of a prestigious Japanese literary award has confirmed AI helped write her book. CNN. https://edition.cnn.com/2024/01/19/style/rie-kudan-akutagawa-prize-chatgpt/index.html
CISAC. (2024, December 2). Global economic study shows human creators’ future at risk from generative AI. CISAC. https://www.cisac.org/Newsroom/news-releases/global-economic-study-shows-human-creators-future-risk-generative-ai
creative professionals. (2024, October 22). Statement on AI training. Statement on AI Training. https://www.aitrainingstatement.org/
Cu, M., & Hochman, sebastian. (2023, January 23). Scores of stanford students used chatgpt on final exams. The Stanford Daily. https://stanforddaily.com/2023/01/22/scores-of-stanford-students-used-chatgpt-on-final-exams-survey-suggests/
Flew, T. (2021). Regulating Platforms. Polity Press.
Office, I. P. (2024, December 17). Copyright and artificial intelligence. GOV.UK. https://www.gov.uk/government/consultations/copyright-and-artificial-intelligence
Study.com. (2023). Productive teaching tool or innovative cheating. Study.com. https://study.com/resources/perceptions-of-chatgpt-in-schools?msockid=0a7d4651d7ba6f912e7853cbd62a6e88
Tang, C. (2024). By the tomato novel as AI training “flower fertilizer”, the network authors jointly said no. Thepaper.cn. https://www.thepaper.cn/newsDetail_forward_28226000
The European Union . (2024, June 13). EU Artificial Intelligence Act. https://artificialintelligenceact.eu/ai-act-explorer/
Thomas, D. (2024, December 12). US media groups warn UK over AI content-scraping rules. @FinancialTimes; Financial Times. https://www.ft.com/content/25650c27-7723-4aa8-8c29-6bc5af47cf3b
U.S. Senate Committee on Commerce, Science, & Transportation. (2024, July 11). Cantwell, Blackburn, Heinrich Introduce Legislation to Increase Transparency, Combat AI Deepfakes & Put Journalists, Artists & Songwriters Back in Control of Their Content. U.S. SCCST. https://www.commerce.senate.gov/2024/7/cantwell-blackburn-heinrich-introduce-legislation-to-combat-ai-deepfakes-put-journalists-artists-songwriters-back-in-control-of-their-content
Weber, R. H., & Springerlink (Online Service. (2010). Shaping Internet Governance: Regulatory Challenges. Springer Berlin Heidelberg.
Be the first to comment